En el anterior post (Proyecto GEOW. Implementando el patrón CQRS) nos adentramos en el funcionamiento del proyecto GEOW que nos va a servir de base para implementar un patrón arquitectónico, CQRS, pensado para dar respuesta a sistemas con alta exigencia de lecturas y escrituras simultáneas.
Informamos el DTO InsertPositionDTO con los valores que deseamos mover a base de datos, y lanzamos una tarea en segundo plano, con el fin de no afectar al movimiento de las figuras en el front-end.



Para ello hemos creado una interfaz gráfica con una serie de figuras geométricas en movimiento. Ahora vamos a ir a la parte de EL DATO.
Cada vez que uno de estos cuadrados cambia de posición envía una trama con sus propias características, y sus nuevas coordenadas. Cada uno de los cuadrados realiza un movimiento cada 300 milisegundos, y he llegado a probar con hasta unas 700 figuras. En estos niveles el software empieza a sufrir, pero más la parte gráfica. Aparentemente el sistema de grabación de coordenadas se mantiene en buena forma.
Vamos a ver, precisamente, este sistema de grabación:
Grabando lotes de coordenadas en BBDD
En el objeto PointObj que representa cada una de las figuras, en el SET de las propiedades X e Y nos encontramos el siguiente código:
[JsonProperty] public int X { get { return _x; } set { if (value >= AnchoLimite || value < 10) { if (this.Y > (AltoLimite / 2)) { this.Direccion = enumDireccion.Arriba; } else { this.Direccion = enumDireccion.Abajo; } } else { _x = value; //Graba la posición DTO.InsertPositionDTO _pos = new DTO.InsertPositionDTO() { CreateDate = DateTime.Now, GUIDObject = this.GUIDObject, PointDesc = this.nombreobjeto, X = _x, Y = this.Y, Height = this.Alto, Width = this.Ancho, Color = this.ColorFigura.Name, idJourney = _idJourney }; Task _recordposition = new Task(() => _negObj.InsertPosition(_pos)); _recordposition.Start(); //Serializa y envía objeto vía UDP string str_object = JsonConvert.SerializeObject(_pos); Task _sendposition = new Task(() => _negUDPObj.EnviarMensaje(str_object)); _sendposition.Start(); } } }
La clase de negocio Neg_BufferPositions que contiene el método InsertPosition tiene el siguiente aspecto:

Para optimizar la escritura en base de datos hemos optado por no enviar cada una de las posiciones, sino irlas acumulando en un buffer (cuyo tamaño se le pasa por parámetro al constructor). vean el método InsertPosition
public void InsertPosition(InsertPositionDTO _position) { while (grabando) { Thread.Sleep(100); } _PositionsBuffer.Add(_position); if (_PositionsBuffer.Count == BufferLen) { grabando = true; List<InsertPositionDTO> positionsToRecord = new List<InsertPositionDTO>(_PositionsBuffer); _PositionsBuffer.Clear(); grabando = false; _recordingObj.InsertPositions(positionsToRecord); } }
Aquí pueden observar como va guardando las posiciones en una lista, hasta que dicha lista tiene el número de elementos especificado para el buffer. En ese momento llamamos a la capa de datos para grabar el lote completo.
El método Flush sirve para guardar las coordenadas restantes. Supongan que se detiene el movimiento desde el front-end, y tenemos 100 elementos guardados en un buffer con capacidad para 300. Para volcar esos 100 elementos del buffer a BBDD sirve esta función.
TransferPositionsToReadModel es un método al margen del funcionamiento de la grabación de coordenadas, por lo que más tarde volveremos a inspeccionarlo.
Vamos a pasar a ver la base de datos. Cuando el buffer está lleno llamamos a una función de nuestra capa de datos llamada InsertPositions a la que le pasamos la lista de posiciones a grabar. Con esta lista montamos un dataTable (empleando las técnicas que se explicaron el el post ¿Son eficientes los ORM?) y le pasamos el dataTable completo a un procedimiento almacenado.
El procedimiento es bien sencillo:
/* drop procedure [write].[InsertPositions] */ ALTER procedure [write].[InsertPositions] @tblPositions typePositions readonly as begin insert into [write].[Positions] (GUIDObject, PointDesc, Height, Width, Color, X, Y, idJourney) select GUIDObject, PointDesc, Height, Width, Color, X, Y, idJourney from @tblPositions end
Permítanme mostrarles el diagrama de base de datos propuesto:

Lo primero que hay que poner de relevancia es la existencia de dos tablas Positions, una para el modelo de escritura, y otra para el modelo de escritura.
Esto nos permite, en primer lugar, adaptar los ajustes de cada una de estas tablas al uso que se va a hacer de ellas. Así por ejemplo, si se fijan a la izquierda, los índices de la tabla de lectura, y los de la tabla de lectura son diferentes.
Además la tabla que más sufre, la de escritura, no acumulará los elementos históricos, de modo que su tamaño se mantendrá contenido. Mientras estamos realizando inserciones, las consultas no se realizarán sobre el estresado modelo de escritura, de modo que teóricamente debería resolverlas sin problemas.
El modelo de lectura si contendrá la información histórica, que podría llegar a ser muy voluminosa. Pero podremos aplicar medidas paliativas para todo ese volumen, sin necesidad de afectar el rendimiento de nuestro modelo de escritura. Estoy pensando, por ejemplo, en particiones temporales mediante funciones de partición, o en procesos de historificación de la información.
Las tareas de administración sobre el modelo de lectura se harán más sencillas de llevar a la práctica pudiendo librarse este modelo de la gran carga que suponen las constantes escrituras. Todo este montaje nos da pie, queridos amigos, a un bonito e interesante post sobre administración de tablas con elevados volúmenes de información., que muy pronto abordaremos.
Lanzando consultas al modelo de lectura, mientras seguimos grabando nuevas posiciones
Volvamos un momento al Fron-End, nuestro adorables cuadrados en movimiento:

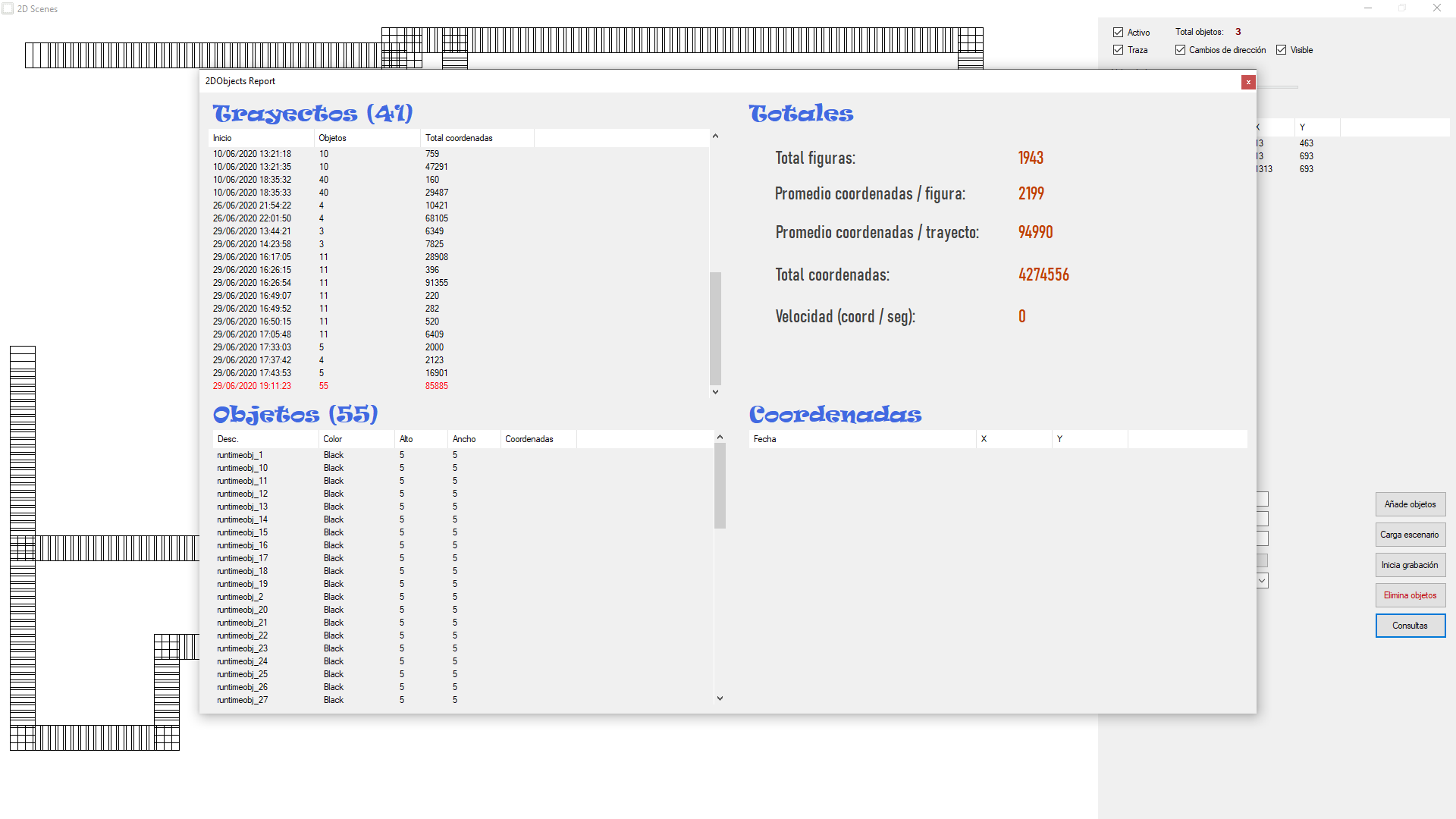
Observen que el último de los botones en la parte izquierda dice "Consultas". Púlsen-lo sin miedo. Se abrirá un formulario como el que ven en la imagen.
El mismo está lanzando periódicamente consultas sobre nuestro modelo de lectura, para ofrecernos información "en tiempo real". Para obtener buenos rendimientos tenemos que asumir un cierto delay entre la grabación en el modelo de escritura, y la transferencia al modelo de lectura. Este delay es el que le da vidilla al sistema.
Vea que si Ud. añade nuevas figuras al PictureBox, al cabo de poco tiempo estas se reflejarán en las consultas. Igualmente se va actualizando el número total de figuras, número total de coordenadas y número total de trayectos (que se forman cada vez que desactivamos/activamos el movimiento de las figuras).
Además si Ud. selecciona un trayecto, lanzará la consulta de los objetos que intervinieron en ese trayecto, y si selecciona un objeto lanzará la consulta del total de coordenadas asociadas a ese trayecto-objeto. También los datos que están activos irán apareciendo (trayecto actual, objetos actuales en movimiento, nuevas coordenadas).
Podrán comprobar Uds. que a pesar de tener numerosos objetos enviando y grabando nuevas coordenadas, el modelo de lectura no pierde por ello eficiencia, esencia ésta del patrón CQRS.
Sincronizando los modelos de lectura/escritura
Naturalmente, para que todo lo visto hasta ahora funcione, en algún momento los datos que van llegando al modelo de escritura deben ser transferidos al de lectura. Es posible que éste sea un buen momento para hacer procesamientos de la información, transformaciones, etc.
Son diversas las posibilidades que existen para crear esta pieza de sincronización de modelos, y no descarto futuras entradas en el blog contraponiendo unas con otras. Puede ser un JOB del agente de SQL Server, puede ser algún tipo de replicación, puede ser un paquete de SSIS...
Para completar el ejemplo de este proyecto he ido a lo más simple, y he construido un procedimiento almacenado al que invoco desde el front-end cada 30 segundos. Este delay tiene que guardar relación con las necesidades específicas del negocio. En este caso los altos ejecutivos del negocio de los cuadrados en movimiento me indican que necesitan información actualizada de los cuadrados, sí o sí, cada 30 segundos.
Vean el procedimiento almacenado y díganme si no les recuerda un poco al David de Miguel Ángel, o las pinturas al fresco de la Capilla Sixtina.
ALTER procedure [write].[TransferPositions] as begin if exists(select 1 from write.Positions) begin create table #guids (guidobject varchar(155)) insert into #guids (guidobject) select distinct GUIDObject from write.Positions nolock --Primero graba los nuevos objetos insert into [dbo].[Points] (PointDesc, Height, Width, Color, GUIDObject) select distinct pos.PointDesc, pos.Height, pos.Width, pos.Color, pos.GUIDObject from write.Positions pos with(nolock) inner join #guids g on pos.GUIDObject = g.guidobject left join [dbo].[Points] p on pos.GUIDObject = p.GUIDObject where p.idPoint is null --A continuación graba los nuevos objetos asociados al correspondiente trayecto insert into [read].[Journeys_Points] (idJourney, idPoint) select distinct pos.idJourney, p.idPoint from write.Positions pos with(nolock) inner join #guids g on pos.GUIDObject = g.guidobject inner join [dbo].[Points] p on pos.GUIDObject = p.GUIDObject where not exists (select 1 from [read].[Journeys_Points] sub where sub.idJourney = pos.idJourney and sub.idPoint = p.idPoint) --Finalmente volcamos las posiciones en el modelo de lectura ALTER TABLE [read].Positions NOCHECK CONSTRAINT FK_Positions_Points ALTER TABLE [read].Positions NOCHECK CONSTRAINT FK_Positions_Journeys delete w output deleted.X, deleted.Y, deleted.dtPosition, deleted.idJourney, p.idPoint into [read].Positions (X, Y, dtPosition, idJourney, idPoint) from write.Positions w inner join #guids g on w.GUIDObject = g.guidobject inner join [dbo].[Points] p on w.GUIDObject = p.GUIDObject ALTER TABLE [read].Positions CHECK CONSTRAINT FK_Positions_Points ALTER TABLE [read].Positions CHECK CONSTRAINT FK_Positions_Journeys drop table #guids end end

Comentarios
Publicar un comentario